constint N = 10005; constint MOD = 1000000007; const ll MOD2 = 1ll * MOD * MOD; int a[N][N], b[N][N];
// 常规写法 intcalc1(int n, int m){ int s = 0; for (int i = 0; i < n; i++) { int sa = 0, sb = 0; for (int j = 0; j < m; j++) { (sa += a[i][j]) %= MOD; (sb += a[i][j]) %= MOD; } int si = (1ll * sa * sb) % MOD; (s += si) %= MOD; } return s; }
// 一次优化写法 intcalc2(int n, int m){ ll s = 0; for (int i = 0; i < n; i++) { ll sa = 0, sb = 0; for (int j = 0; j < m; j++) { sa += a[i][j]; sb += b[i][j]; } ll si = sa * sb; (s += si) %= MOD; } return s; }
// 二次优化写法 intcalc3(int n, int m){ ll s = 0; for (int i = 0; i < n; i++) { ll sa = 0, sb = 0; for (int j = 0; j < m; j++) { sa += a[i][j]; sb += b[i][j]; } ll si = sa * sb; s += si; if (s >= MOD2) s -= MOD2; } return s % MOD; }
// 二次优化+偷懒写法 intcalc4(int n, int m){ ll s = 0; for (int i = 0; i < n; i++) { ll sa = accumulate(a[i], a[i] + m, 0ll); ll sb = accumulate(b[i], b[i] + m, 0ll); ll si = sa * sb; s += si; if (s >= MOD2) s -= MOD2; } return s % MOD; }
一次优化原理如下,由于 $\sum_{j=1}^m {a_{ij}} $ 和 $ \sum_{j=1}^m {b_{ij}}$ 都在 [0,108] 范围内,所以可以用 long long 存下,所以 si=(∑j=1maij)×(∑j=1mbij)∈[0,1016] 也可以用 long long 存下,但由于最终的 s 是在 [0,1020] 超出了 long long的表达范围,所以需要对 s 的加法结果进行取模。
二次优化原理如下,由于实际long long可以表达到 [−263,263−1] 范围,263 约等于 9∗1018。我们可以使用 MOD2 作为 s 的模数,最终返回的时候再对 MOD 取模一次,正确性可以通过数论证明,这里不做展开,那么 s 只有大约 1001 的概率实际需要进行取模,在平时题目中,这个概率是不确定的但往往是比较小的一个概率,那么使用 if 来判定然后做减法,往往会比取模效率提高非常多。
int n, m; // a表示题目输入的a,b,b来存放当前i的i^k的所有数字的a,b组合 pii a[N], b[N]; // c表示当前枚举集合的第j个=数字要选的时候需要被减去几次 int c[N] = {0}; // 表示当前i是否被访问过,比如需要跳过4,8,9之类的数字 bool vis[N]; ll rst;
voiddfs(int k, ll w){ if (k > m) { rst = max(rst, w); return; } dfs(k + 1, w); w += b[k].first; w -= 1ll * b[k].second * c[k]; for (int i = k; i <= m; i += k) { c[i]++; } dfs(k + 1, w); for (int i = k; i <= m; i += k) { c[i]--; } }
voidsolve(){ while (cin >> n) { memset(vis, false, sizeof(vis)); for (int i = 1; i <= n; i++) cin >> a[i].first; for (int i = 1; i <= n; i++) cin >> a[i].second;
ll ans = a[1].first; for (int i = 2; i <= n; i++) { if (vis[i]) continue; m = 0; for (ll k = i; k <= n; k *= i) { vis[k] = true; b[++m] = a[k]; } rst = 0; dfs(1, 0); ans += rst; } cout << ans << endl; } }
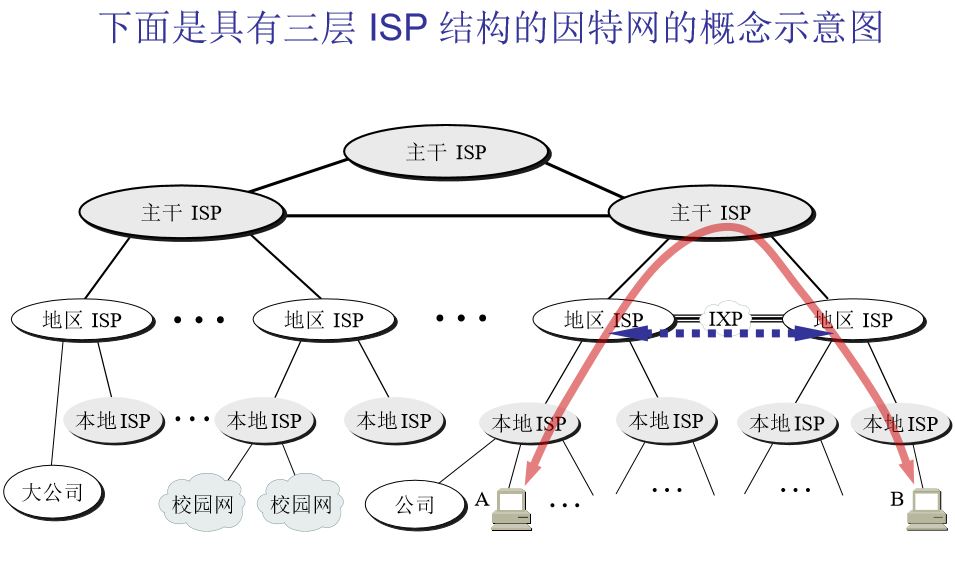
处在因特网边缘的部分就是连接在因特网上的所有的主机。这些主机又称为端系统(end system)。
“主机 A 和主机 B 进行通信”,实际上是指:“运行在主机 A 上的某个程序和 运行在主机 B 上的另一个程序进行通信”。
即“主机 A 的某个进程和主机 B 上的另一个进程进行通信”。或简称为“计算机之间通信”
constint N = int(1e5 + 10); constint M = int(2e5 + 10); int a[N]; int n, m, h;
inlineboolcheck(int u, int v){ return a[u] + 1 == a[v] || a[u] + 1 == a[v] + h; }
int head[N], tot; pii eg[M];
voidaddEdge(int u, int v){ eg[tot] = {v, head[u]}; head[u] = tot++; }
int dfn[N], low[N], st[N], belong[N], num[N]; bool inst[N]; int idx, top, scc;
voidtarjan(int u){ dfn[u] = low[u] = ++idx; st[top++] = u; inst[u] = true; for (int i = head[u]; i != -1; i = eg[i].second) { int v = eg[i].first; if (!dfn[v]) { tarjan(v); low[u] = min(low[u], low[v]); } elseif (inst[v]) { low[u] = min(low[u], dfn[v]); } } int v; if (dfn[u] == low[u]) { scc++; do { v = st[--top]; inst[v] = false; belong[v] = scc; num[scc]++; } while (u != v); } }
voidwork(){ fill_n(dfn, n + 1, 0); fill_n(num, n + 1, 0); fill_n(inst, n + 1, false); idx = top = scc = 0; for (int i = 1; i <= n; i++) { if (!dfn[i]) tarjan(i); } }
bool g[N];
voidsolve(){ while (cin >> n >> m >> h) { for (int i = 1; i <= n; i++) { cin >> a[i]; } tot = 0; fill_n(head, n + 1, -1); rep(i, 0, m) { int u, v; cin >> u >> v; if (check(u, v)) { addEdge(u, v); } if (check(v, u)) { addEdge(v, u); } } work(); fill_n(g, n + 1, 0); for (int u = 1; u <= n; u++) { for (int i = head[u]; ~i; i = eg[i].second) { int v = eg[i].first; if (belong[u] == belong[v])continue; g[belong[u]] = true; } } int mn = -1; for (int i = 1; i <= scc; i++) { if (g[i]) continue; if (mn == -1 || num[i] < num[mn]) { mn = i; } } cout << num[mn] << endl; for (int i = 1, c = 0; i <= n; i++) { if (belong[i] == mn) { cout << i << " \n"[++c == num[n]]; } } } }
intfroot(int s){ int l, r, mn = N, rt = 0; q[l = r = 1] = s; while (l <= r) { int u = q[l++]; sz[u] = 1; smx[u] = 0; for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].to; if (v == fa[u] || vis[v]) continue; fa[v] = u; q[++r] = v; } } // 反向遍历所有点算size while (--l) { int u = q[l]; int mx = max(smx[u], r - sz[u]); if (mx < mn) mn = mx, rt = u; if (l == 1) break; // 根节点没有fa sz[fa[u]] += sz[u]; smx[fa[u]] = max(smx[fa[u]], sz[u]); } return rt; }
// sons子树方向节点个数, val根到该节点异或和, gc边后继方向的节点个数 int sons[N], gc[M]; ll val[N]; ll ans = 0; int n;
constint MOD = int(1e9 + 7);
ll nums[N]; int cnt[N];
voidgo(int s, int rt){ fa[s] = rt; val[s] = 0; int l, r; // 不计算s q[l = r = 0] = s; int m = 0; while (l <= r) { int u = q[l++]; nums[m++] = val[u]; for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].to; if (v == fa[u] || vis[v]) continue; fa[v] = u; q[++r] = v; val[v] = val[u] ^ gh.eg[i].w; // 这个点方向后面有多少点 sons[v] = gc[i]; } } sort(nums, nums + m); m = unique(nums, nums + m) - nums; mst(cnt, 0, m); // 遍历分支 for (int j = gh.head[s]; ~j; j = gh.eg[j].nxt) { // 分支的根 int du = gh.eg[j].to; if (vis[du]) continue; q[l = r = 1] = du; while (l <= r) { int u = q[l++]; int k = lower_bound(nums, nums + m, val[u]) - nums; (ans += 1ll * sons[u] * cnt[k] % MOD) %= MOD; if (val[u] == 0) { (ans += 1ll * sons[u] * (n - gc[j]) % MOD) %= MOD; } for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].to; if (v == fa[u] || vis[v]) continue; q[++r] = v; } } // 增加这个方向的值 while (--l) { int u = q[l]; int k = lower_bound(nums, nums + m, val[u]) - nums; (cnt[k] += sons[u]) %= MOD; } } }
voidwork(int u){ // 换根 u = froot(u); vis[u] = true; go(u, 0); for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].to; if (vis[v]) continue; work(v); } }
// 预处理边后继节点个数 intpdfs(int u, int f){ int fg_id = -1; int s = 1; for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].to; if (v == f) { // 记录父边ID fg_id = i; continue; } int c = pdfs(v, u); gc[i] = c; s += c; } // 存在父边 if (~fg_id) gc[fg_id] = n - s; return s; }
voidsolve(){ while (cin >> n) { gh.init(n); for (int i = 2; i <= n; i++) { int u, v; ll w; u = i; cin >> v >> w; gh.addEdge(u, v, w); gh.addEdge(v, u, w); } mst(vis, false, n + 1); pdfs(1, 0); ans = 0; work(1); cout << ans << endl; } }
inlinevoidaddEdge(int x, int y, ll v){ eg[cnt] = Edge(y, v, head[x]); head[x] = cnt++; }
inlineintbegin(int p){ return head[p]; }
inline Edge &operator[](int i) { return eg[i]; }
inlineintnext(int i){ return eg[i].nxt; } } gh;
structTreeChain { int top[N]; // 链条顶端点ID int fa[N]; // 父亲节点 int son[N]; // 重儿子 int deep[N]; // 深度 int num[N]; // 儿子节点数(包括自己)
int p[N]; // 点在线段树中的ID int fp[N]; // 线段树中ID对应的点 int fe[N]; // 每个点到父亲节点的边ID int ep[N]; // 每个点到父节点对应的边在线段树中的ID // int fep[N]; // 线段树中ID对应的边 int tot;
voiddfs(int u, int pre, int d){ num[u] = 1; deep[u] = d; fa[u] = pre; son[u] = -1; fe[u] = -1; for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].e; if (v == pre) { fe[u] = i; continue; } dfs(v, u, d + 1); num[u] += num[v]; if (son[u] == -1 || num[v] > num[son[u]]) { son[u] = v; } } }
voidgetpos(int u, int sp){ top[u] = sp; p[u] = tot++; fp[p[u]] = u; ep[fe[u] >> 1] = p[u]; if (son[u] == -1) return; getpos(son[u], sp); for (int i = gh.head[u]; ~i; i = gh.eg[i].nxt) { int v = gh.eg[i].e; if (v == son[u] || v == fa[u]) continue; getpos(v, v); } }
voidbuild(int start, int root){ tot = start; // start是线段树中的ID起始数值 dfs(root, 0, 0); getpos(root, root); } } treec;
voidchange(int pos, ll v){ for (int i = pos; i < n; i += i & (-i)) c[i] ^= v; }
ll query(int x){ ll ans = 0; for (int i = x; i > 0; i -= i & (-i)) ans ^= c[i]; return ans; }
ll query(int l, int r){ if (r < l) swap(l, r); return query(r) ^ query(l - 1); } } tree;
ll query(int u, int v){ int f1 = treec.top[u]; int f2 = treec.top[v]; ll ans = 0; while (f1 != f2) { if (treec.deep[f1] < treec.deep[f2]) { swap(f1, f2); swap(u, v); } ans ^= tree.query(treec.p[f1], treec.p[u]); u = treec.fa[f1]; f1 = treec.top[u]; } if (treec.deep[u] > treec.deep[v]) { swap(u, v); } ans ^= tree.query(treec.p[u], treec.p[v]); return ans; }
int _tc = 0; int val[N];
voidsolve(){ int n, m, q; cin >> n >> q; m = n - 1; gh.init(n); tree.init(n); rep(i, 0, m) { int a, b; cin >> a >> b; gh.addEdge(a, b, 0); gh.addEdge(b, a, 0); } rep(i, 0, n) { cin >> val[i + 1]; val[i + 1]++; } treec.build(1, 1); rep(i, 0, n) { int p = treec.p[i + 1]; tree.change(p, val[i + 1]); } rep(i, 0, q) { int c, x, y; cin >> c >> x >> y; if (c == 1) { ll ans = query(x, y); cout << (ans - 1) << endl; } else { tree.change(x, val[x]); tree.change(x, val[x] = y + 1); } } }